몽고DB의 고가용성 시스템인 복제 셋을 소개하며 아래와 같은 내용을 다뤄보자
- 복제 셋의 정의
- 복제 셋을 설정하는 방법
- 복제 셋 멤버 구성 옵션
10.1 복제 소개
서버를 단일로 사용하면 매우 위험하다
복제는 데이터의 동일한 복사본을 여러 서버상에서 보관하는 방법이며 실제 서비스를 배포할 때 권장된다
한 대 또는 그 이상의 서버에 이상이 발생하더라도, 복제는 애플리케이션이 정상적으로 동작하게 하고 데이터를 안전하게 보존한다
몽고DB를 사용하면 복제 셋을 생성함으로써 복제를 설정할 수 있다
복제 셋은 클라이언트 요청을 처리하는 프라이머리 서버 한 대와, 프라이머리 데이터의 복사본을 갖는 세컨더리 서버 여러 대로 이루어진다
프라이머리 서버에 장애가 발생하면 세컨더리 서버는 자신들 중에서 새로운 프라이머리 서버를 선출할 수 있다
10.2 복제 셋 설정 - 1장
# r1, r2, r3 3개의 디렉터리 생성
mkdir -p ~/Mongo/data/rs{1,2,3}
./mongod -replSet mdbDefGuide --dbpath ~/Mongo/data/rs1 --port 27017 --oplogSize 200
./mongod -replSet mdbDefGuide --dbpath ~/Mongo/data/rs2 --port 27018 --oplogSize 200
./mongod -replSet mdbDefGuide --dbpath ~/Mongo/data/rs3 --port 27019 --oplogSize 200
—smallfiles는 mongo 4.2부터 지원되지 않음
10.3 네트워크 고려 사항
복제 셋의 모든 멤버는 같은 셋 내 다른 멤버와 연결할 수 있어야 한다 (자기 자신을 포함)
mongod는 기본적으로 로컬호스트(127.0.0.1)에만 바인딩 된다
복제 셋의 각 멤버가 다른 멤버와 통신하려면 다른 멤버가 연결할 수 있는 IP 주소에도 바인딩해야 한다
./mongod --bind_ip localhost, 192.51.100.1 --replSet mdbDefGuide \\
--dbpath ~/Mongo/data/s1 --port 27017 --oplogSize 200
10.4 보안 고려 사항
localhost 이외의 IP 주소에 바인딩하기 전 복제 셋을 구성할 때, 권한 제어를 활성화하고 인증 메커니즘을 지정해야 한다
또한, 디스크의 데이터를 암호화하고, 복제 셋 멤버 간 통신 및 셋과 클라이언트 통신을 암호화하면 좋다
10.5 복제 셋 설정 - 2장
위의 mongod가 다른 mongod의 존재를 알수있도록 해보자
각 멤버를 나열하는 구성을 만들어 mongod 프로세스 중 하나로 보내면 서로 존재를 알 수 있다
mongod 인스턴스 중 하나에 연결하는 mongo 셸을 시작해보자
mongo --port 27017
# 구성 도큐먼트를 만들고 rs.initiate() 보조자에 전달해 복제 셋을 시작
rsconf = {
_id : "mdbDefGuide",
members: [
{_id:0, host:"localhost:27017"},
{_id:1, host:"localhost:27018"},
{_id:2, host:"localhost:27019"}
]
}
# rsconf = { _id: "mdbDefGuide", members: [ {_id:0, host:"localhost:27017"}, {_id:1, host:"localhost:27018"}, {_id:2, host:"localhost:27019"} ] }
rs.initiate(rsconf)
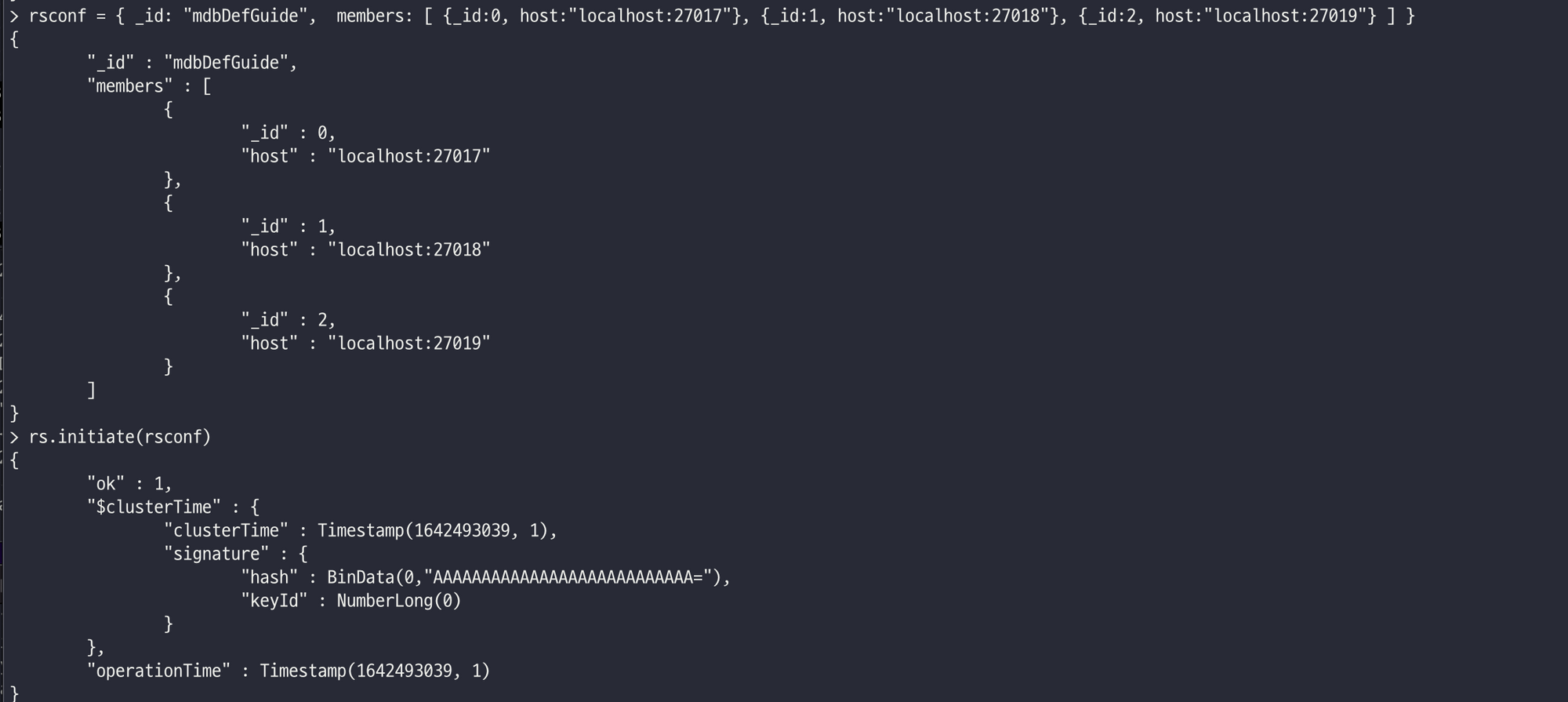
이렇게 3개의 멤버가 있는 복제 셋이 시작되며 구성을 나머지 mongod들에 전파해 복제 셋이 형성된다
복제 셋 구성 도큐먼트에는 몇 가지 중요한 부분이 있다
_id는 명령행에 전달한 복제 셋의 이름이다 (ex. mdbDefGuide)
각 멤버의 _id는 정수이며 복제 셋 멤버 간에 고유해야 한다
독립 실행형 서버는 다운타임 없이 복제 셋으로 변환할 수 없지만, 복제 셋으로 구성되어 있으면 나중에 다운타임 없이 멤버를 추가할 수 있다 (단일 멤버도 복제 셋으로 구성할 수 있다)
복제 셋의 상태는 rs.status()를 사용해서 볼 수 있다
10.6 복제 관찰
복제 셋이 포트 27017에 있는 mongod를 프라이머리로 선출했다면, 복제 셋을 시작하는 데 사용된 mongod 셸이 현재 프라이머리에 연결돼 있다

이는 _id가 mdbDefGuide인 복제 셋 프라이머리에 연결됐음을 뜻한다
Insert (From PRIMARY)
이제 1000개의 도큐먼트를 삽입해보자
# test db로 change
use test
for (i=0; i<1000; i++) {db.coll.insert({count:i})}
db.coll.count()

확인 (From SECONDARY)
이제 세컨더리에 모든 도큐먼트의 사본이 있는지 확인해보자
먼저, 프라이머리의 test db에 대한 연결을 사용해 isMaster() 명령을 실행해보자
(이는 rs.status()보다 훨씬 더 간결한 형태로 복제 셋의 상태를 보여준다)
애플리케이션 코드를 작성하거나 스크립팅할 때 어느 멤버가 프라이머리인지 판별하는 편리한 방법이다
mdbDefGuide:PRIMARY> db.isMaster()
{
"topologyVersion" : {
"processId" : ObjectId("61e67021287d0ecc1d9a2837"),
"counter" : NumberLong(6)
},
"hosts" : [
"localhost:27017",
"localhost:27018",
"localhost:27019"
],
"setName" : "mdbDefGuide",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "localhost:27017",
"me" : "localhost:27017",
"electionId" : ObjectId("7fffffff0000000000000001"),
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1642493590, 1),
"t" : NumberLong(1)
},
"lastWriteDate" : ISODate("2022-01-18T08:13:10Z"),
"majorityOpTime" : {
"ts" : Timestamp(1642493590, 1),
"t" : NumberLong(1)
},
"majorityWriteDate" : ISODate("2022-01-18T08:13:10Z")
},
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 100000,
"localTime" : ISODate("2022-01-18T08:13:14.133Z"),
"logicalSessionTimeoutMinutes" : 30,
"connectionId" : 2,
"minWireVersion" : 0,
"maxWireVersion" : 9,
"readOnly" : false,
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1642493590, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1642493590, 1)
}
어느 시점이든 선출이 호출되고 연결돼 있던 mongod가 세컨더리가 되면 isMaster()를 사용해 어느 멤버가 프라이머리가 됐는지 확인할 수 있다
이제 세컨더리 연결을 인스턴스화해보자
mdbDefGuide:PRIMARY> secondaryConn = new Mongo("localhost:27019")
connection to localhost:27019
mdbDefGuide:PRIMARY> secondaryDB = secondaryConn.getDB("test")
test
그리고 세컨더리로 복제된 컬렉션에 읽기를 시도하면 오류가 발생한다
mdbDefGuide:PRIMARY> secondaryDB.coll.find()
Error: error: {
"topologyVersion" : {
"processId" : ObjectId("61e66ffe68bbd16cebe50047"),
"counter" : NumberLong(4)
},
"operationTime" : Timestamp(1642493930, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotPrimaryNoSecondaryOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1642493930, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
세컨더리는 프라이머리보다 뒤쳐지며 데이터가 최신이 아닐 수 있다
세컨더리는 실수로 실효 데이터를 읽지 않도록 기본적으로 읽기 요청을 거부한다
따라서 세컨더리를 쿼리하려고 하면 프라이머리가 아니라는 오류가 표시된다
세컨더리에 대한 쿼리를 허용하려면 다음처럼 설정한다
secondaryConn.setSlaveOk()
# setSlaveOk는 데이터베이스(secondaryDB)가 아니라 연결(secondaryConn)에 설정
이제 정상적으로 읽어진다
mdbDefGuide:PRIMARY> secondaryDB.coll.find()
{ "_id" : ObjectId("61e67628ba41459d941690ee"), "count" : 0 }
{ "_id" : ObjectId("61e67628ba41459d941690ef"), "count" : 1 }
{ "_id" : ObjectId("61e67628ba41459d94169100"), "count" : 18 }
{ "_id" : ObjectId("61e67628ba41459d941690f9"), "count" : 11 }
{ "_id" : ObjectId("61e67628ba41459d941690fa"), "count" : 12 }
{ "_id" : ObjectId("61e67628ba41459d94169107"), "count" : 25 }
{ "_id" : ObjectId("61e67628ba41459d94169133"), "count" : 69 }
{ "_id" : ObjectId("61e67628ba41459d9416913d"), "count" : 79 }
{ "_id" : ObjectId("61e67628ba41459d94169140"), "count" : 82 }
{ "_id" : ObjectId("61e67628ba41459d94169143"), "count" : 85 }
{ "_id" : ObjectId("61e67628ba41459d94169156"), "count" : 104 }
{ "_id" : ObjectId("61e67628ba41459d94169161"), "count" : 115 }
{ "_id" : ObjectId("61e67628ba41459d9416916c"), "count" : 126 }
{ "_id" : ObjectId("61e67628ba41459d9416916e"), "count" : 128 }
{ "_id" : ObjectId("61e67628ba41459d94169178"), "count" : 138 }
{ "_id" : ObjectId("61e67628ba41459d9416917f"), "count" : 145 }
{ "_id" : ObjectId("61e67628ba41459d94169180"), "count" : 146 }
{ "_id" : ObjectId("61e67628ba41459d941691a9"), "count" : 187 }
{ "_id" : ObjectId("61e67628ba41459d941691c8"), "count" : 218 }
{ "_id" : ObjectId("61e67628ba41459d941691ce"), "count" : 224 }
Type "it" for more
이제 세컨더리에 쓰기를 해보면 에러가 발생한다
세컨더리는 클라이언트가 아닌 복제를 통해 가져오는 쓰기만 가능하다
mdbDefGuide:PRIMARY> secondaryDB.coll.insert({"count":1001})
WriteCommandError({
"topologyVersion" : {
"processId" : ObjectId("61e66ffe68bbd16cebe50047"),
"counter" : NumberLong(4)
},
"operationTime" : Timestamp(1642494200, 1),
"ok" : 0,
"errmsg" : "not master",
"code" : 10107,
"codeName" : "NotWritablePrimary",
"$clusterTime" : {
"clusterTime" : Timestamp(1642494200, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
})
자동 장애 조치(automatic failover)라는 기능을 시도해보자
프라이머리가 중단되면 세컨더리 중 하나가 자동으로 프라이머리로 선출된다
한번 프라이머리를 중단해보고 어느 멤버가 프라이머리가 됐는지 확인해보자
db.adminCommand({"shutdown":1})
> secondaryDB.isMaster()
{
"topologyVersion" : {
"processId" : ObjectId("61e66ffe68bbd16cebe50047"),
"counter" : NumberLong(5)
},
"hosts" : [
"localhost:27017",
"localhost:27018",
"localhost:27019"
],
"setName" : "mdbDefGuide",
"setVersion" : 1,
"ismaster" : false,
"secondary" : true,
"primary" : "localhost:27018",
"me" : "localhost:27019",
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1642494353, 1),
"t" : NumberLong(2)
},
"lastWriteDate" : ISODate("2022-01-18T08:25:53Z"),
"majorityOpTime" : {
"ts" : Timestamp(1642494353, 1),
"t" : NumberLong(2)
},
"majorityWriteDate" : ISODate("2022-01-18T08:25:53Z")
},
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 100000,
"localTime" : ISODate("2022-01-18T08:25:56.097Z"),
"logicalSessionTimeoutMinutes" : 30,
"connectionId" : 31,
"minWireVersion" : 0,
"maxWireVersion" : 9,
"readOnly" : false,
"ok" : 1,
"$clusterTime" : {
"clusterTime" : Timestamp(1642494353, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1642494353, 1)
}
프라이머리가 27018로 전환됐다
프라이머리의 중단을 가장 먼저 발견한 세컨더리가 선출된다
다음 핵심 개념을 기억해두자
- 클라이언트는 독립 실행형 서버에 보낼 수 있는 모든 작업을 프라이머리 서버에 보낼 수 있다
- (읽기, 쓰기, 명령, 인덱스 구축 등)
- 클라이언트는 세컨더리에 쓰기를 할 수 없다
- 기본적으로 클라이언트는 세컨더리로부터 읽을 수 없다
- secondaryConn.setSlaveOk() 설정을 통해 읽기를 활성화할 수 있다
10.7 복제 셋 구성 변경
복제 셋 구성은 언제든지 변경할 수 있다
(멤버 추가, 삭제, 변경이 가능하다)
# 새로운 멤버 추가
rs.add("localhost:27020")
# 멤버 제거
rs.remove("localhost:27017")
# 재구성 성공 여부는 rs.config()로 확인 가능
rs.config()
# 구성을 변경할 때 마다 “version” 필드 값이 증가 (default : 1)
# 멤버 변경
var config = rs.config()
config.members[0].host = "localhost:27017"
rs.reconfig(config)
10.8 복제 셋 설계 방법
복제 셋을 설계하기에 앞서 과반수 개념을 알아둬야 한다
프라이머리를 선출하려면 멤버의 과반수 이상이 필요하고, 프라이머리는 과반수 이상이어야만 프라이머리 자격을 유지할 수 있다
또한 쓰기는 과반수 이상에 복제되면 안전해진다
과반수는 복제 셋내 모든 멤버의 절반보다 많은 것’ 으로 정의된다
| 복제 셋 내 멤버의 수 | 복제 셋의 과반수 |
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 4 |
| 7 | 4 |
과반수는 복제 셋의 구성에 따라 산정되므로, 얼마나 많은 멤버가 다운되거나 사용할 수 없는 상태인지는 중요하지 않다
예를 들어, 복제 셋 멤버가 5개이고, 그 중 3개가 다운됐고, 2개가 살아있다고 가정해보자
2개의 멤버는 복제 셋의 과반수에 미치지 않으므로 프라이머리를 선출할 수 없다 (최소 3개이상)
만약 둘 중 하나가 프라이머리였다면, 두 멤버가 과반수에 미치지 않는다는 것을 알자마자 프라이머리 자격을 내려놓는다
몇 초 후 확인해보면 복제 셋은 두 개의 세컨더리와 세 개의 통신이 안되는 멤버로 구성된다
몽고DB가 프라이머리 하나 이상을 갖도록 지원하면 해결이 될 껏이다
하지만 다중 마스터는 그 자체로 복잡성을 수반한다 (ex. 쓰기 충돌)
따라서 몽고DB는 오직 단일 프라이머리만 지원한다
그 결과 개발이 쉬워질 수 있지만 복제 셋이 읽기 전용 상태일 때는 어느 정도 시간이 걸린다
어떻게 선출하는가
세컨더리가 프라이머리가 되지 못하면 다른 멤버들에 이를 알리고 자신을 프라이머리로 선출할 것을 요청한다
요청을 받은 멤버들은 아래와 같은 검사를 한다
- 요청받은 멤버가 프라이머리에 도달할 수 있는가?
- 선출되고자 하는 멤버의 복제 데이터가 최신인가?
- 대신 선출돼야 하는 우선순위가 더 높은 멤버는 없는가?
몽고DB는 3.2에서 복제 프로토콜 버전 1을 도입했다
프로토콜 버전 1은 스탠퍼드 대학에서 개발한 RAFT 합의 프로토콜을 기반으로 한다
아비터, 우선순위, 비투표 멤버, 쓰기 결과 확인 등 몽고DB 특유의 복제 개념을 포함한다
복제 셋 멤버는 2초마다 서로 핑을 보낸다
10초 이내 멤버가 핑을 보내지 않으면, 다른 멤버가 그 불량 멤버를 접근할 수 없음으로 표시한다
어떤 멤버가 프라이머리로 선출되려면 복제 데이터가 최신이어야 한다
복제된 모든 작업은 오름차순 식별자에 따라 엄격하게 정렬되므로, 후보는 도달할 수 있는 모든 멤버보다 작업이 늦거나 같아야 한다
10.9 멤버 구성 옵션
특정 멤버가 우선적으로 프라이머리가 되게 하거나, 클라이언트에 보이지 않게 해 읽기 요청이 라우팅되지 않도록 할 수 있다
1. 우선 순위
우선순위는 특정 멤버가 얼마나 프라이머리가 되기를 ‘원하는지’를 나타내느 지표다
우선순위는 0~100 사이 값으로 지정할 수 있으며 default는 1이다
멤버의 우선순위를 0으로 지정하면 절대 프라이머리가 될 수 없다. (passive memer라고 한다)
우선순위가 높은 멤버는 언제나 프라이머리로 선출된다 (복제 셋이 과반수이고 데이터가 가장 최신인 경우)
데이터가 최신으로 동기화되지 못하면 선출되지 않는다
2. 숨겨진 멤버
클라이언트는 숨겨진 멤버(hidden member)에 요청을 라우팅하지 않으며, 숨겨진 멤버는 복제 소스로서 바람직하지 않다
따라서 많은 이들이 백업 서버를 숨긴다
서버를 숨기려면 hidden: true 필드를 구성에 추가해야 하고, 우선순위가 0이어야 한다 (프라이머리는 숨길 수 없다)
멤버를 다시 노출시키려면 hidden 옵션을 false로 변경하거나 제거하면 된다
3. 아비터 선출
멤버가 2개인 복제 셋은 대부분의 요구 사항에서 명확한 단점이 있다
하지만 소규모로 배포하는 사람들은 데이터 복사본을 세 개나 보관하기를 꺼린다
복사본은 2개면 충분하고, 3개의 복사본은 관리, 운영, 비용을 고려하면 별 가치가 없다고 생각하기 때문이다
이런 배포에 대해 몽고DB는 프라이머리 선출에 참여하는 용도로만 쓰이는 아비터라는 특수한 멤버를 지원한다
아비터는 데이터를 가지지 않으며 클아이언트에 의해 사용되지 않는다
오로지 2-멤버 복제 셋에서 과반수를 구성하는 데 사용된다
일반적으로 아비터가 없는 배포가 바람직하다
아비터는 mongod 서버 작동과는 아무런 연관이 없다
아비터는 일반적으로 몽고DB에 사용하는 서버보다 사양이 낮은 서버에서 경량화 프로세스로 실행할 수 있다
—replSet name 옵션과 빈 데이터 디렉터리를 이용해 시작할 수 있다
rs.addArb("server-5:27017")
rs.add({"_id":4, "host":"server-5:27017", "arbiterOnly" :true})
아비터는 복제 셋에 추가되면 영원히 아비터이다
아비터를 아비터가 아닌 것으로 재구성하는 것은 불가능하다
또한, 아비터는 큰 클러스터상에서 동점 상황을 없앨 수 있다는 장점이 있다
노드 개수가 짝수이면 절반은 한 멤버에 투표하고 나머지는 다른 멤버에 투표할 수 있다
이때 아비터를 추가하면 투표 결과를 결정지을 수 있다
주의사항
아비터는 최대 하나까지만 사용하라
노드의 개수가 홀수이면 아비터는 필요하지 않다
짝수이면 1개가 필요하므로 아비터는 최대 1개만 필요하다
아비터를 추가한다고 선출 속도가 빨라지지 않으며, 추가적인 데이터 안정성을 제공하지도 않는다
아비타 사용의 단점
데이터 노드와 아비터 중 하나를 골라야 한다면 데이터 노드를 선택하자
작은 규모의 복제 셋에서 데이터 노드 대신 아비터를 사용하면 운영 업무가 더 어려워질 수 있다
예를 들어 일반 멤버 2개와 아비터로 구성된 복제 셋 중 데이터를 보관하는 멤버 하나가 다운된다고 가정해보자
해당 멤버 서버가 복구가 어려운 상황이라면 세컨더리로 사용중인 서버쪽으로 복제본을 가져와야 한다
데이터 복사는 서버에 상당한 부하를 줄 수 있으며 애플리케이션이 느려질 수 있다
반대로 데이터를 보관하는 멤버가 3개라면 하나가 완전히 죽더라도 일단 괜찮다
프라이머리에 의지하는 대신, 남아 있는 세컨더리를 이용해 새로운 서버를 독자적으로 실행할 수 있다
멤버 둘에 아비터가 추가된 경우, 프라이머리는 마지막으로 남아 있는 정상적인 데이터의 복제본이자, 또 다른 복제본을 온라인으로 가져오는 동안 애플리케이션으로부터 부하를 조절하는 개체다
따라서 가능하다면 아비터 대신 홀수 개의 일반 멤버를 추가하는 것이 좋다
4. 인덱스 구축
때때로 세컨더리는 프라이머리에 존재하는 것과 동일한 인덱스를 갖지 않아도 된다
인덱스가 없어도 된다
세컨더리를 데이터 백업이나 오프라인 배치 작업에만 사용한다면 buildIndexes : false로 설정하자
이는 영구적인 설정이며 다시는 일반 멤버로 재구성될 수 없다
위와 같은 옵션을 사용하려면 멤버의 우선순위가 0이어야 한다
'MongoDB' 카테고리의 다른 글
| [MongoDB] Ch12 - 애플리케이션에서 복제 셋 연결 (0) | 2022.01.24 |
|---|---|
| [MongoDB] Ch11 - 복제 셋 구성 요소 (0) | 2022.01.21 |
| [MongoDB] Ch9 - 애플리케이션 설계 (0) | 2022.01.11 |
| [MongoDB] Ch8 - 트랜잭션 (0) | 2022.01.04 |
| [MongoDB] Ch7 - 집계 프레임워크 (0) | 2022.01.04 |




댓글